
强化微调 (RFT) 提供了一种提升模型在特定任务上表现的方法。该任务必须明确,且答案可验证。
何时使用强化微调
智能体工作流旨在做出既正确又可验证的决策。RFT 可以通过提供明确的规则,并使用基于代码或 LLM 的评分器来衡量功能是否成功、事实是否准确或是否符合策略,从而在这方面提供帮助。
在早期用户中,涌现出了三个明确的用例:
- 将指令转化为可用代码:将开放式提示转换为结构化的代码、配置或模板,且必须通过确定性测试。
- 将事实提取为整洁的格式:从杂乱的非结构化文本中提取可验证的事实和摘要,并返回 JSON 结构化或其他基于 Schema 的输出。
- 正确应用复杂规则:当提供的信息具有细微差别、数量庞大、层次分明或风险极高时,进行细粒度的标签或策略决策。
1. 将指令转化为可用代码
在此用例中,模型会对隐藏的领域约束进行推理,以生成结构化输出,如代码、查询或基础设施模板。输出必须满足多个正确性条件,且成功与否通常采用确定性评分:生成的产物要么能够编译、通过测试,要么符合明确的模式。
为半导体设计布线验证 IP
公司: ChipStack 正在构建下一代由 AI 驱动的芯片设计和验证工具,旨在显著降低开发和验证复杂半导体芯片的时间与成本。
待解决的问题:对人类来说一项极具挑战且耗时的工作就是将设计接口绑定到验证 IP(预先创建的验证组件,如果正确应用,可以显著提高验证的质量和覆盖率)。验证 IP 数量众多,每个 IP 可能包含数十到数百个可映射的信号。必须对该领域有深入了解才能正确应用验证 IP。
目标:为了训练 OpenAI 推理模型来完成这项工作,ChipStack 准备了一个包含不到 50 个样本的数据集,然后进行了多种 RFT 变体训练。在最终评估报告中,他们对每个模型和变体(o1-mini 基础版和微调版、o3-mini 基础版和微调版)运行了三次该评估集,并计算了每个样本及整体的平均结果。
以下是一段提供的示例数据。
[
{“name”: “BLOCK_SIZE”, “value”: “8”},
{“name”: “ADDR_WIDTH”, “value”: “4”}
]以下是 Python 中字符串映射的评分器定义,表示为包含以下内容的对象列表
nameandvalueproperties.在概念上,这旨在对类似以下的类型进行建模
Dict[str, str].
{
"type": "python",
"name": "donors_caas",
"image_tag": "alpha",
"source": "from collections import Counter
def grade(sample: dict[str, str], item: dict[str, str]) -> float:
# multisets of (name, value) pairs
predicted = sample[\"output_json\"][\"predicted\"]
expected = item[\"reference_answer\"]
pred_counts = Counter((d[\"name\"], d[\"value\"]) for d in predicted)
exp_counts = Counter((d[\"name\"], d[\"value\"]) for d in expected)
true_pos = sum(min(pred_counts[p], exp_counts[p]) for p in pred_counts)
pred_total = sum(pred_counts.values())
exp_total = sum(exp_counts.values())
precision = true_pos / pred_total if pred_total else 0.0
recall = true_pos / exp_total if exp_total else 0.0
if precision + recall == 0.0:
return 0.0
return 2 * precision * recall / (precision + recall)"
}对于 o1-mini 和 o3-mini,性能均提升了约 12 个百分点。经过微调的变体在判断何时不应应用布线方面表现得更加出色。许多商用验证 IP 可能包含数百个可选信号,其中大部分并不适合被应用。
“借助强大的基础模型和易于使用的强化微调 API,我们能够仅用少量高质量样本,就显著提升了任务的表现。”
—ChipStack,下一代 AI 驱动的芯片设计和验证工具
可投入生产且能通过 AST 检查的 API 代码片段
公司: Runloop 是一个用于将 AI 驱动的编码智能体部署到生产环境的平台,该平台具备公共和自定义基准测试功能,以优化性能。
待解决的问题:Runloop 希望提高模型使用第三方 API(如 Stripe API)的性能,这些 API 可能非常庞大且复杂,无需人工干预。如果他们能够训练模型使用 Stripe API,Runloop 就可以将具有经济效益的商业案例转化为可运行的代码。
目标:他们的目标是让模型掌握 Stripe API 的使用,包括通过改编现有集成指南中的信息、合并多个指南中的信息或推断指南中未明确说明的信息,为任意用户请求编写完整的代码片段。他们使用了带有两个主要奖励函数的 RFT:
- 当模型以符合“动态”集成指南预期的 Markdown 格式输出答案时,给予模型奖励。
- 通过 AST Grep 验证输出的代码,当模型生成“正确”的代码片段时给予奖励。这使得他们能够确认模型是否使用了正确的 Stripe SDK 调用及正确的参数,在某些情况下甚至能确认调用顺序的正确性。
# Note this file gets uploaded to the OpenAI API as a grader
from ast_grep_py import SgRoot
from pydantic import BaseModel, Field # type: ignore
from typing import Any, List, Optional
import re
SUPPORTED_LANGUAGES = ['typescript', 'javascript', 'ts', 'js']
class CodeBlock(BaseModel):
language: str = Field(
description="Programming language of the code block (e.g., 'python', 'javascript')",
examples=["python", "javascript", "typescript"]
)
path: str = Field(
description="Target file path where the code should be written",
examples=["main.py", "src/app.js", "index.html"]
)
code: str = Field(
description="Actual code content extracted from the code block"
)
class ASTGrepPattern(BaseModel):
file_path_mask: str = Field(..., description="The file path pattern to match against")
pattern: str = Field(..., description="The main AST grep pattern to search for")
additional_greps: Optional[List[str]] = Field(
default=None,
description="Additional patterns that must also be present in the matched code"
)
def extract_code_blocks(llm_output: str) -> List[CodeBlock]:
# Regular expression to match code blocks with optional language and path
try:
pattern = r"```(\w+\s+)?([\w./-]+)?\n([\s\S]*?)\n```"
matches = list(re.finditer(pattern, llm_output, re.DOTALL))
print(f"Found {len(matches)} code blocks in the LLM output")
# Check if any code blocks were found
if not matches:
raise Exception("No code blocks found in the LLM response")
code_blocks: list[CodeBlock] = []
for match in matches:
language = match.group(1) or ""
path = match.group(2) or ""
code = match.group(3)
# Clean the path and language
path = path.strip()
language = language.strip()
# If path is relative (doesn't start with /), prefix with /home/user/testbed/
if path and not path.startswith("/"):
original_path = path
path = f"/home/user/testbed/{path}"
print(
f"Converting relative path '{original_path}' to absolute path '{path}'"
)
code_blocks.append(
CodeBlock(language=language, path=path, code=code.strip())
)
# Check for missing language or path in code blocks
missing_language = [
i for i, block in enumerate(code_blocks) if not block.language
]
missing_path = [i for i, block in enumerate(code_blocks) if not block.path]
if missing_language:
print(
f"WARNING: Code blocks at positions {missing_language} are missing language identifiers"
)
raise Exception(
f"Code blocks at positions {missing_language} are missing language identifiers"
)
if missing_path:
print(
f"WARNING: Code blocks at positions {missing_path} are missing file paths"
)
raise Exception(
f"Code blocks at positions {missing_path} are missing file paths"
)
paths = [block.path for block in code_blocks if block.path]
print(
f"Successfully extracted {len(code_blocks)} code blocks with paths: {', '.join(paths)}"
)
except Exception as e:
print(f"Error extracting code blocks: {str(e)}")
raise
return code_blocks
def calculate_ast_grep_score(code_blocks: List[CodeBlock], ast_greps: Any) -> float:
# Convert ast_greps to list if it's a dict
if isinstance(ast_greps, dict):
ast_greps = [ast_greps]
# Parse each grep pattern into the Pydantic model
parsed_patterns: List[ASTGrepPattern] = []
for grep in ast_greps:
try:
pattern = ASTGrepPattern(**grep)
parsed_patterns.append(pattern)
except Exception as e:
print(f"Error parsing AST grep pattern: {e}")
return 0.0
if not parsed_patterns:
return 0.0
total_score = 0.0
pattern_count = len(parsed_patterns)
# Filter code blocks to only include TypeScript and JavaScript files
supported_blocks = [
block for block in code_blocks
if block.language.lower() in SUPPORTED_LANGUAGES
]
if not supported_blocks:
print("No TypeScript or JavaScript code blocks found to analyze")
return 0.0
for pattern in parsed_patterns:
# Find matching code blocks based on path prefix
matching_blocks = [
block for block in supported_blocks
if block.path.startswith(pattern.file_path_mask)
]
if not matching_blocks:
print(f"No matching code blocks found for path prefix: {pattern.file_path_mask}")
continue
pattern_found = False
for block in matching_blocks:
try:
# Create AST root for the code block
root = SgRoot(block.code, block.language)
node = root.root()
# Check main pattern
matches = node.find(pattern=pattern.pattern)
if not matches:
continue
# If we have additional greps, check them too
if pattern.additional_greps:
all_additional_found = True
for additional_grep in pattern.additional_greps:
if additional_grep not in block.code:
all_additional_found = False
break
if not all_additional_found:
continue
# If we get here, we found a match with all required patterns
pattern_found = True
break
except Exception as e:
print(f"Error processing code block {block.path}: {e}")
continue
if pattern_found:
total_score += 1.0
# Return average score across all patterns
return total_score / pattern_count if pattern_count > 0 else 0.0
def grade_format(output_text: str) -> float:
# Find <plan> and </plan> tags
plan_start = output_text.find('<plan>')
plan_end = output_text.find('</plan>')
# Find <code> and </code> tags
code_start = output_text.find('<code>')
code_end = output_text.find('</code>')
reward = 0.0
if plan_start == -1 or plan_end == -1 or code_start == -1 or code_end == -1:
print(f'missing plan or code tags. format reward: {reward}')
return reward
reward += 0.1 # total: 0.1
if not (plan_start < plan_end < code_start < code_end):
print(f'tags present but not in the correct order. format reward: {reward}')
return reward
reward += 0.1 # total: 0.2
# Check if there are any stray tags
plan_tags = re.findall(r'</?plan>', output_text)
code_tags = re.findall(r'</?code>', output_text)
if len(plan_tags) != 2 or len(code_tags) != 2:
print(f'found stray plan or code tags. format reward: {reward}')
return reward
reward += 0.2 # total: 0.4
# Extract content after </code> tag
after_tags = output_text[code_end + len('</code>'):].strip()
if after_tags:
print(f'found text after code tags. format reward: {reward}')
return reward
reward += 0.2 # total: 0.6
# Extract content inside <plan> tags
plan_content = output_text[plan_start + len('<plan>'):plan_end].strip()
if not plan_content:
print(f'no plan content found. format reward: {reward}')
return reward
reward += 0.1 # total: 0.7
# Extract content inside <code> tags
code_content = output_text[code_start + len('<code>'):code_end].strip()
if not code_content:
print(f'no code content found. format reward: {reward}')
return reward
reward += 0.1 # total: 0.8
# Extract content between </plan> and <code> tags
between_tags = output_text[plan_end + len('</plan>'):code_start].strip()
if between_tags:
print(f'found text between plan and code tags. format reward: {reward}')
return reward
reward += 0.2 # total: 1.0
if reward == 1.0:
print(f'global format reward: {reward}')
return reward
def grade(sample: Any, item: Any) -> float:
try:
output_text = sample["output_text"]
format_reward = grade_format(output_text)
if format_reward < 1.0:
return format_reward
# Extract code content for grading
code_start = output_text.find('<code>')
code_end = output_text.find('</code>')
code_to_grade: str = output_text[code_start + len('<code>'):code_end].strip()
code_blocks: List[CodeBlock] = []
try:
code_blocks = extract_code_blocks(code_to_grade)
except Exception as e:
print(f'error extracting code blocks: {e}')
return 0.5
ast_greps = item["reference_answer"]["ast_greps"]
ast_grep_score = calculate_ast_grep_score(code_blocks, ast_greps)
return (format_reward + ast_grep_score) / 2.0
except Exception as e:
print(f"Error during grading: {str(e)}")
return 0.0综合考察总奖励(格式和 AST Grep)来看,Runloop 实现了平均 12% 的 RFT 模型与基准 o3-mini 模型在基准测试上的对比。
他们实施了两种类型的测试:一种是提供来自集成指南的显式内容(评估推理和指令遵循能力),另一种则不提供(评估知识回忆能力)。两种变体的提升幅度均超过 8%.
“OpenAI 的 RFT 平台让我们能够使用世界上最优秀的通用推理模型,并提供了相应的工具集,可以在对我们业务至关重要的问题领域内极大地增强这种推理能力。”
正确处理日程管理器中的冲突和重复项
公司: Milo 帮助忙碌的父母管理混乱的家庭日程,它能将杂乱的输入(例如包含待办事项的文本对话、学校简报 PDF、每周提醒、体育日程邮件等)转化为可靠的日历和列表操作。
待解决的问题:GPT-4o 的基础提示和 SFT 未能达到信任阈值。
目标:Milo 使用 RFT 来正确创建编码任务,例如事件与列表分类、循环规则生成、精确的更新和删除、冲突检测以及严格的输出格式化。他们定义了一个评分器,用于检查生成的项目对象是否完整、分类是否正确,以及是否重复或存在日历冲突。
结果显示各项性能均有提升,平均正确性得分 从 0.86 提升至 0.91,同时最具挑战性的场景提升了 0.46 to 0.71 (满分为 1)。
“准确性不仅仅是一项指标,更是忙碌父母的安心之所。现在仍处于早期阶段,但在基础性能取得了如此重大的提升之后,我们能够更加积极地推进对复杂推理需求的满足。”
“理解和支持家庭动态涉及对数据隐含意义的深入把握。以冲突为例——要知道 Ethan 的足球比赛与 Ella 的独奏会在时间上冲突,是因为爸爸必须开车送他们俩去,这远比单纯的时间重叠要复杂得多。”
—Milo,面向家庭的 AI 日程安排工具
2. 将事实提取为整洁的格式
这些任务通常涉及微妙的区分,需要明确的分类指南。成功的框架构建需要通过领域专家的共识来定义显式且分层级的标签方案。如果没有一致的共识,评分信号就会变得嘈杂,从而削弱 RFT 的效果。
分配 ICD-10 医疗代码
公司: Ambience 是一个 AI 平台,旨在减轻临床医生的管理负担,确保 100 多个专科的文档准确且合规,帮助医生专注于患者护理,同时提高医疗系统的文档质量并降低合规风险。
待解决的问题:ICD-10 编码是医学中最复杂的行政任务之一。每次患者就诊后,临床医生必须将每项诊断映射到约 70,000 个代码中的一个——需遵循付款方关于特异性、就医场所和互斥配对的具体规则。错误可能会引发审计和高达九位数的巨额罚款。
目标:通过对 OpenAI 前沿模型使用强化微调,Ambience 希望训练一个推理系统,该系统能够听取就诊音频,提取相关的 EHR 上下文,并推荐准确度超越临床专家的 ICD-10 代码。
Ambience 实现了可赶超人类专家的模型提升。
在一个涵盖数百次就诊的金标专家组测试集中,强化微调使模型从落后于人类转变为领先人类 12 个百分点——消除了受过专业训练的医生大约四分之一的编码错误:
- o3-mini(基准版):0.39(-6 分)
- 医生基准线:0.45
- 经过 RFT 调优的 o3-mini:0.57(+12 分)
其成果是一种实时的护理点编码支持,既能提高报销的准确性,又能降低合规风险。
“准确的 ICD-10 选择对于合规文档至关重要。RFT 释放了我们从未在任何基础模型中见过的全新水平的编码精确度,并为自动化编码树立了新标杆。”
提取摘录以支持法律主张
公司: Harvey 正在打造值得法律团队信赖的 AI,而这种信赖取决于能否从海量的合同、法规和案例库中检索出最精准的证据。法律专业人士并不满足于仅仅生成听起来合理的摘要或释义的模型。他们需要可验证的引用——能够直接追溯至源文档的段落。
待解决的问题:Harvey 的客户使用其模型来评估诉讼风险、构建法律论点,并为法律专业人员提供尽职调查支持——在这些任务中,遗漏或错误引用单句话语都可能改变最终结果。模型必须能够解析冗长密集的法律文件,并仅提取其中关键的部分。实际上,这些输入通常杂乱且不一致:一些声明含糊不清,而另一些则依赖于深埋在格式化条款中的罕见法律原则。
目标:任务要求是解读细微的法律声明、浏览长篇文档,并选择带有逐字摘录的准确依据。
## Instructions
You will be provided with a question and a text excerpt. Identify any passages in the text that are directly relevant to answering the question.
- If there are no relevant passages, return an empty list.
- Passages must be copied **exactly** from the text. Do not paraphrase or summarize.
## Excerpt
"""{text_excerpt}"""from rapidfuzz import fuzz
# Similarity ratio helper
def fuzz_ratio(a: str, b: str) -> float:
"""Return a normalized similarity ratio using RapidFuzz.
"""
if len(a) == 0 and len(b) == 0:
return 1.0
return fuzz.ratio(a, b) / 100.0
# Main grading entrypoint (must be named `grade`)
def grade(sample: dict, item: dict) -> float:
"""Compute an F1‑style score for citation extraction answers using RapidFuzz.
"""
model_passages = (sample.get('output_json') or {}).get('passages', [])
ref_passages = (item.get('reference_answer') or {}).get('passages', [])
# If there are no reference passages, return 0.
if not ref_passages:
return 0.0
# Recall: average best match for each reference passage.
recall_scores = []
for ref in ref_passages:
best = 0.0
for out in model_passages:
score = fuzz_ratio(ref, out)
if score > best:
best = score
recall_scores.append(best)
recall = sum(recall_scores) / len(recall_scores)
# Precision: average best match for each model passage.
if not model_passages:
precision = 0.0
else:
precision_scores = []
for out in model_passages:
best = 0.0
for ref in ref_passages:
score = fuzz_ratio(ref, out)
if score > best:
best = score
precision_scores.append(best)
precision = sum(precision_scores) / len(precision_scores)
if precision + recall == 0:
return 0.0
return 2 * precision * recall / (precision + recall)经过强化微调后,Harvey 看到了 提升 20% in the F1 score:
- 基线 F1:0.563
- RFT 后 F1 - 0.6765
通过使用 RFT,Harvey 显著提升了法律事实抽取的性能,在效率和准确性上双双超越了 GPT-4o。早期测试显示,RFT 在与 GPT-4o 的对比中, 在 93% 的情况下获胜或持平 与 GPT-4o 相比。
“RFT 模型展现出了与 GPT-4o 相当甚至更优的性能,且推理速度显著加快,这对于现实世界中的法律用例尤为有益。
—Harvey,面向法律团队的 AI
3. 正确应用复杂规则
该用例涉及从非结构化输入中提取可验证的事实或实体,并将其转化为明确定义的结构(例如 JSON 对象、条件代码、医疗代码、法律引用或财务指标)。
成功的提取任务通常得益于精确、连续的评分方法(如 span 级别的 F1 分数、模糊文本匹配指标或数值准确性检查),以评估提取的信息与真实值的吻合程度。请定义明确的成功标准和详细的评分规则。之后,模型就能实现可靠的、可重复的改进。
税务分析中的专家级推理
公司: Accordance 正在为税务、审计和 CPA 团队构建一个平台。
待解决的问题:税务是一个高度复杂的领域,需要对细微的事实模式和错综复杂的法规进行深度推理。这也是一个不断变化的领域。
目标:Accordance 希望为复杂的税务场景构建一个高信任度的系统,同时保持准确性。与传统的硬编码软件不同,他们的数据提取工具必须能够随着税收环境的演变而自适应。
[+0.05] For correctly identifying Alex (33.33%), Barbara (33.33% → 20%), Chris (33.33%), and Dana (13.33%) ownership percentages
[+0.1] For correctly calculating Barbara's annual allocation as 26.67% and Dana's as 6.67% without closing of books
[+0.15] For properly allocating Alex ($300,000), Barbara ($240,030), Chris ($300,000), and Dana ($60,030) ordinary income
[+0.1] For calculating Alex's ending stock basis as $248,333 and debt basis as $75,000
[+0.05] For calculating Barbara's remaining basis after sale as $264,421
[+0.1] For calculating AAA before distributions as $1,215,000 and ending AAA as $315,000
[+0.1] For identifying all distributions as tax-free return of capital under AAA
[+0.1] For calculating Barbara's capital gain on stock sale as $223,720 ($400,000 - $176,280)
[+0.1] For explaining that closing of books would allocate based on actual half-year results
[+0.05] For identifying the ordering rules: AAA first, then E&P ($120,000), then remaining basis
[+0.05] For noting distributions exceeding $1,215,000 would be dividends up to $120,000 E&P
[+0.05] For correctly accounting for separately stated items in basis calculations (e.g., $50,000 Section 1231 gain)通过与 OpenAI 及其内部税务专家合作,Accordance 实现了:
- 几乎 40% 的提升 在税务分析任务中优于基础模型
- 在 TaxBench 等基准测试中表现优于所有其他领先模型
- 经过 RFT 训练的模型展现了以高准确度处理高级税务场景的能力——在由税务专业人士进行评估时,Accordance 的微调模型展现出了专家级的推理能力,有望节省数千小时的手动工作
“我们在税务分析任务中取得了较基础模型 38.89% 的提升,并在关键税务基准测试(包括 TaxBench)中显著优于所有其他领先模型。经过 RFT 训练的模型在处理复杂税务场景的同时保持了准确性,证明了强化微调——以及更广泛的人工智能技术——在专业应用领域的成熟度。最重要的是,RFT 为税务环境演变时的持续适应奠定了基础,确保了持续的价值与相关性。在税务专家的评估中,我们的微调模型展现出了专家级的推理能力,这将节省数千小时的专业工作时间——这不仅仅是渐进式的改进,而是税务工作方式的一次范式转变。”
—Accordance,一家 AI 税务会计公司
执行细致的内容审核政策
公司: SafetyKit 是一个风险与合规平台,旨在帮助组织在复杂的内容审核工作流中做出决策。
待解决的问题:这些系统必须处理海量内容,并应用需要多步推理的复杂策略逻辑。由于数据量庞大且标签分类存在细微差异,这类任务对于通用模型而言可能颇具挑战。
目标:SafetyKit 旨在通过使用强化微调模型,用单一的推理智能体取代其最复杂工作流中的多个节点。其目标是即使在充满挑战和细微差别的领域,也能缩短 SafetyKit 针对新策略执行上市所需的时间。
SafetyKit 正在使用其 o3-mini RFT 模型来支持高级内容审核功能,为全球最大的 AI 聊天机器人公司之一确保用户安全。他们已成功提升了 F1 分数 from 86% to 90%,不久后将取代其生产流水线中的数十次 4o 调用。
“SafetyKit 基于 RFT 的审核在细微内容审核任务中取得了显著改进,这对于在动态的真实场景中保护用户至关重要。”
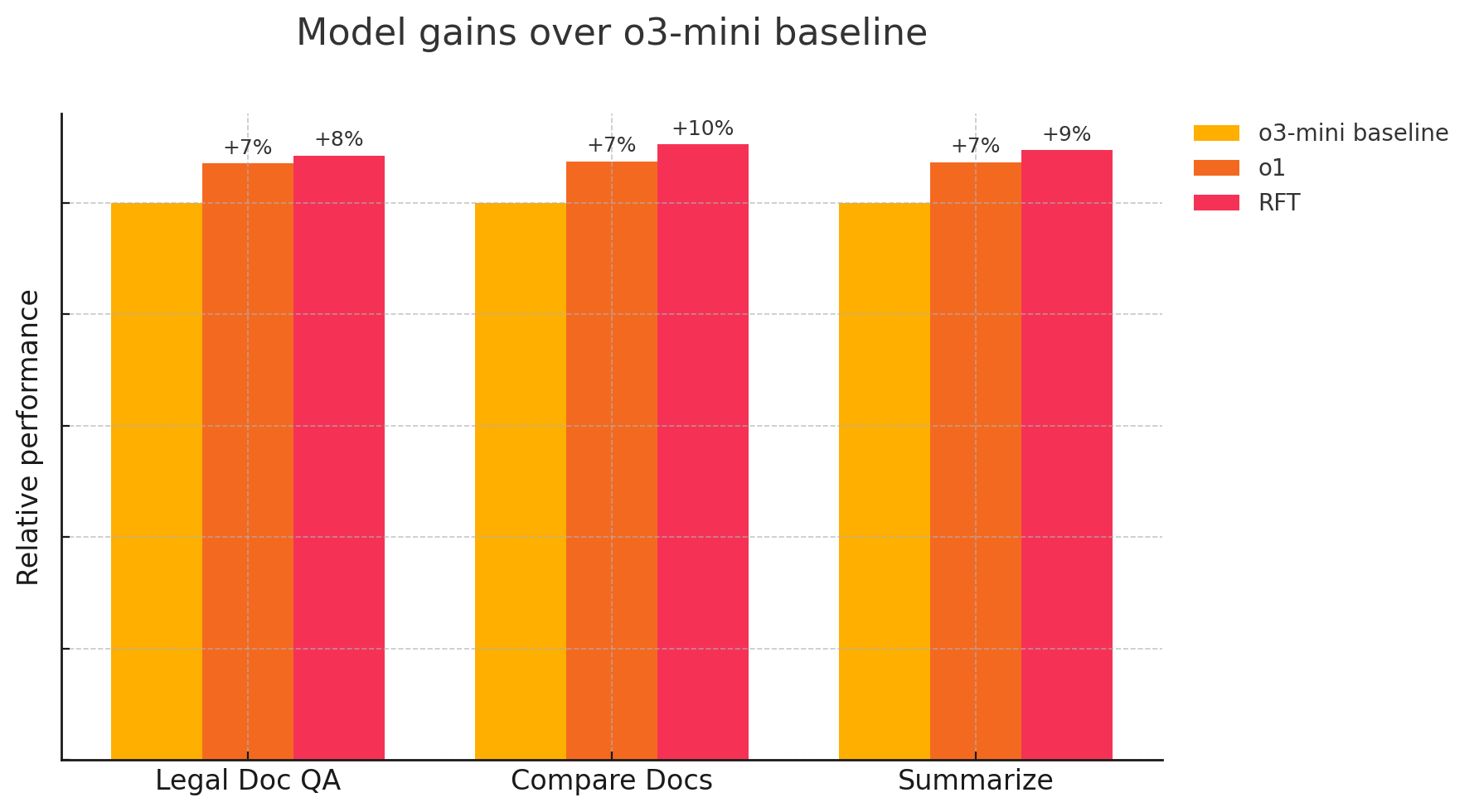
法律文件审查、比较和摘要
公司: Thomson Reuters 是一家人工智能和技术公司,致力于通过值得信赖的内容和工作流自动化为专业人士赋能。
待解决的问题: 法律专业人士在做出任何决定之前,都必须阅读大量内容。Thomson Reuters 的 CoCounsel 产品旨在通过为这些专家提供具备内容和行业知识的 AI 助手,帮助他们提高工作效率。支持该工具的模型必须理解复杂的法律规则。
目标:Thomson Reuters 旨在创建一个在法律 AI 技能方面表现卓越的强化微调模型。他们对 RFT 进行了初步评估,以探讨是否能实现模型性能的提升,评估使用了来自 CoCounsel 中法律专业人士最常用的三项法律 AI 技能的专用数据集:
- 审查文件:针对合同、笔录及其他法律文件生成所提问题的详细解答
- 比较文件:突出显示两份或多份不同合同或文件之间的实质性差异
- 摘要:总结一份或多份文件中最重要的信息,以实现快速的法律审查
“‘LLM 裁判’有助于证明改进推理模型的可能性——在初步评估中,RFT 模型始终表现优于基线 o3-mini 和 o1 模型”
—Thomson Reuters,一家 AI 与技术公司
评估是基础
在实施 RFT 之前,我们强烈建议为您打算微调的任务创建并运行评估。如果你打算微调的模型得分已经达到了可能的绝对最低分或绝对最高分,那么 RFT 对你将没有用处。
RFT 的工作原理是强化对所提供提示的更优答案。如果我们无法区分不同答案的质量(即,如果它们都获得了可能的最低分或最高分),那么就没有可供学习的训练信号。然而,如果您的评估得分介于可能的最低分和最高分之间,则有足够的数据可供处理。
有效的评估能够揭示人类专家持续达成共识但当前前沿模型却感到棘手的机会,从而为 RFT 提供了一个有待弥合的宝贵差距。 开始使用评估.
如何从 RFT 中获得更好的结果
要想看到微调模型的改进,有两个主要方面需要回顾和优化:确保您的任务定义清晰,以及使您的评分方案更加稳健。
重构或明确您的任务
好的任务能为模型提供公平的学习机会,并让您能够量化改进效果。
- 从模型已经能够偶尔解决的任务开始。RFT 的工作原理是对多个答案进行采样,保留看起来最好的答案,并引导模型向这些答案靠拢。如果模型目前从未给出过正确答案,它就无法得到改进。
- 确保每个答案都能被评分。评分器必须能够在没有人工干预的情况下读取答案并给出评分。我们支持多种 评分器类型,包括自定义 Python 评分器和 LLM 评委。如果你无法使用可用的评分器编写代码来评判答案,那么 RFT 就不是合适的工具。
- 消除对“正确”答案的疑问。如果两个严谨的人经常对解决方案产生分歧,说明任务定义过于模糊。请重写提示词、补充上下文,或将任务拆分为更清晰的子任务,直到该领域的专家达成共识。
- 限制侥幸猜对。如果任务是只有唯一明显最佳选项的选择题,模型可能会凭运气得分。请增加选项类别、要求提供简短的开放性文本,或调整格式以提高盲目猜测的代价。
强化您的评分器
清晰、稳健的评分方案对于 RFT 至关重要。
- 生成平滑的分数,而非简单的及格/不及格判定。随着答案质量的提升而逐渐变化的分数,能提供更好的训练信号。
- 防范奖励作弊。当模型找到一种无需真正技能就能获得高分的捷径时,就会出现这种情况。
- 避免数据倾斜。当数据集中某个标签在大多数时候出现时,会诱使模型直接猜测该标签。请平衡数据集或提高稀有案例的权重,以促使模型进行思考。
- 当代码力有不逮时,请使用 LLM 裁判。对于内容丰富的开放性回答,请使用 使用单独的 OpenAI 模型来评分 您的微调模型的答案。请确保您:
- 评估裁判:将多个候选回答和参考答案输入到你的 LLM 评委中运行,以确保返回的评分稳定且符合偏好。
- 提供少样本示例。在提示词中包含优秀、一般和较差的答案示例,以提高评分器的有效性。
了解更多 评分器类型.
其他资源
获取更多灵感,请访问 OpenAI Cookbook, 其中包含示例代码和指向第三方资源的链接,或者了解更多关于我们的模型和推理能力的信息: