本文档介绍了 Realtime API 的计费方式,并提供了优化成本的策略。语音代理会话在文本、音频和图像模态上累计输入和输出 token。流式翻译和流式转录会话按音频时长计费。价格因模型而异,具体价格列在模型页面上(例如, gpt-realtime-2, gpt-realtime-translate, gpt-realtime-whisper,且 gpt-realtime).
对话式 Realtime API 会话由一系列 轮次,其中用户添加的输入会触发一个 响应 以生成模型输出。服务器会维护一个 对话, 这是一个列表,包含 Items ,构成下一轮的输入。返回响应时,输出会自动添加到对话中。
翻译和转录会话使用不同的流式架构。客户端持续流式传输音频,并在源音频到达时接收翻译后的音频、转录增量或转录事件。这些会话不使用常规的响应生命周期,因此应使用基于时长的费率而非按响应的 token 使用量来估算和监控它们。
按响应计算的成本
Realtime API 的成本在创建响应时产生,并根据输入和输出的 token 数量计费(输入转录成本除外,见下文)。目前不收取网络带宽或连接费用。响应可以手动创建,也可以在开启语音活动检测 (VAD) 时自动创建。VAD 会有效过滤掉空的输入音频,因此除非客户端手动将其添加为对话输入,否则空音频不计为输入 token。
每次响应都会将整个对话发送给模型。一轮的输出将作为项目添加到服务器的对话中,并成为后续轮次的输入,因此会话中较晚出现的轮次将更加昂贵。
文本 token 成本可以使用我们的 分词工具。用户消息中的音频令牌为每 100 毫秒音频 1 个令牌,而助手消息中的音频令牌为每 50 毫秒音频 1 个令牌。请注意,令牌计数包含特殊令牌,除消息内容外,这会导致计数中出现细微差异,例如,包含 10 个文本令牌内容的用户消息可能会计为 12 个令牌。
示例
这里有一个简单的例子,用来说明多轮 Realtime API 会话的 token 成本。
对于对话中的第一轮,我们添加了 100 个 token 的指令、一条包含 20 个音频 token 的用户消息(例如由 VAD 根据用户的语音添加),总计 120 个输入 token。创建响应会生成一条助手输出消息(20 个音频 token,10 个文本 token)。
然后我们用另一条用户音频消息创建第二轮。第二轮的 token 会是什么样?此时的对话包括初始指令、第一条用户消息、第一轮的助手输出消息,以及第二条用户消息(25 个音频 token)。这一轮将有 110 个文本和 64 个音频 token 作为输入,外加另一条助手输出消息的输出 token。
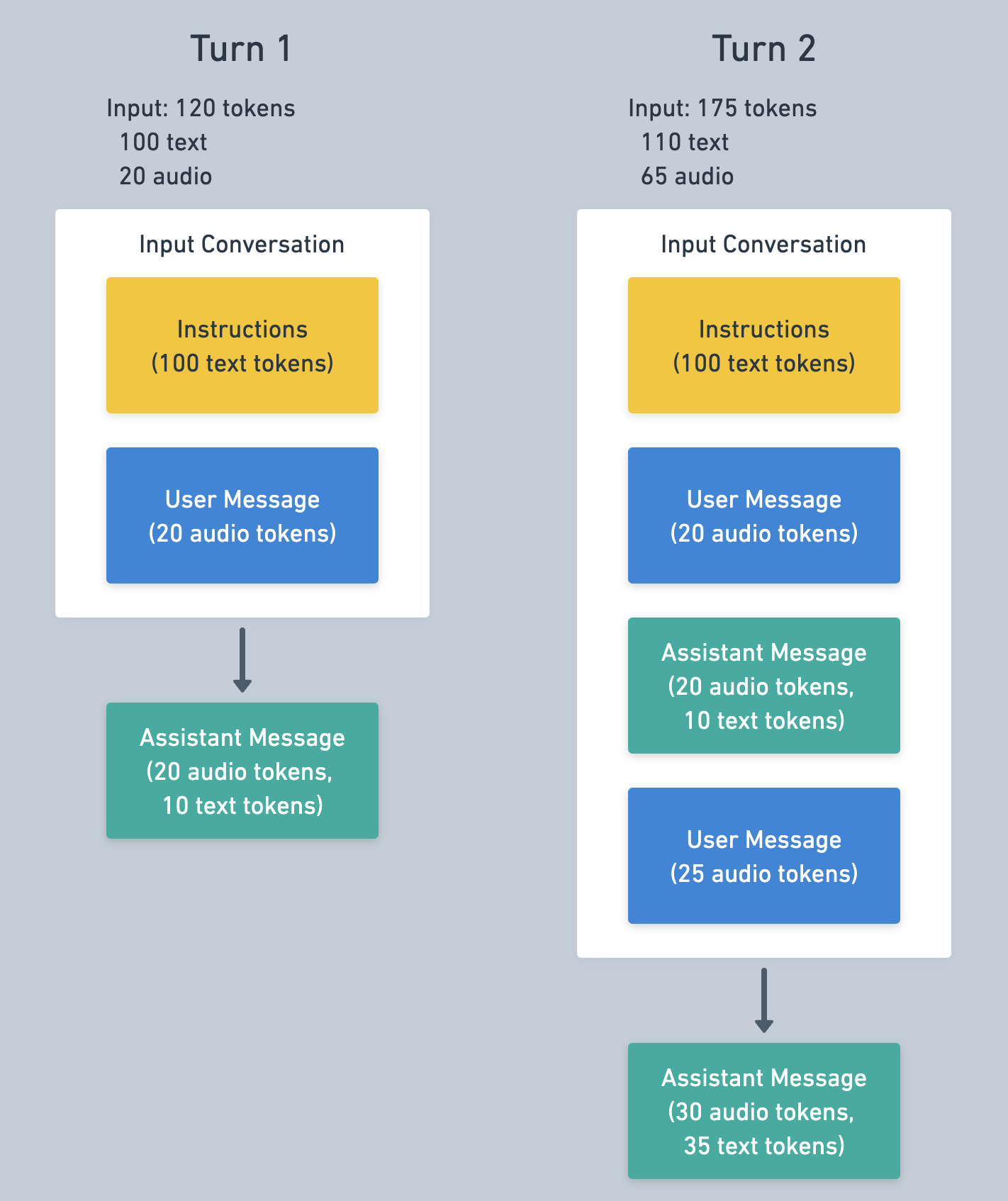
第一轮的消息可能会为第二轮缓存,从而降低输入成本。有关缓存的更多信息,请参见下文。
响应使用的 token 可以从 response.done 事件中读取,如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
{
"type": "response.done",
"response": {
...
"usage": {
"total_tokens": 253,
"input_tokens": 132,
"output_tokens": 121,
"input_token_details": {
"text_tokens": 119,
"audio_tokens": 13,
"image_tokens": 0,
"cached_tokens": 64,
"cached_tokens_details": {
"text_tokens": 64,
"audio_tokens": 0,
"image_tokens": 0
}
},
"output_token_details": {
"text_tokens": 30,
"audio_tokens": 91
}
}
}
}输入转录成本
除了对话响应之外,如果启用,Realtime API 还会对输入转录进行计费。输入转录使用的模型与 speech2speech 模型不同,例如 whisper-1 or gpt-4o-transcribe,因此按照不同的费率标准进行计费。当音频被写入输入音频缓冲区并被提交时(手动提交或由 VAD 提交),将执行转录。
输入转录的 token 数量可以从 conversation.item.input_audio_transcription.completed 事件中读取,如下例所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
{
"type": "conversation.item.input_audio_transcription.completed",
...
"transcript": "Hi, can you hear me?",
"usage": {
"type": "tokens",
"total_tokens": 26,
"input_tokens": 17,
"input_token_details": {
"text_tokens": 0,
"audio_tokens": 17
},
"output_tokens": 9
}
}缓存
Realtime API 支持 提示缓存,它会自动应用,并且可以大幅降低多轮对话期间输入令牌的成本。当 Response 的输入令牌与先前 Response 的令牌匹配时,将应用缓存,但这是尽力而为的操作,无法保证。
最大化缓存命中率的最佳策略是保持会话历史记录静止。删除或更改对话中的内容会使缓存失效,失效范围直到发生更改的位置——输入将不再像以前那样大量匹配。请注意,指令和工具定义位于对话的开头,因此在会话中途更改这些内容会降低后续轮次的缓存命中率。
截断
当对话中的 token 数量超过模型的输入 token 限制时,对话将被截断,这意味着(从最旧的开始)消息将从响应输入中被丢弃。一个具有 4,096 个最大输出 token 的 32k 上下文模型,在发生截断之前,上下文中最多只能包含 28,224 个 token。
客户端可以设置小于模型最大值的 token 窗口,这是控制 token 使用量和成本的好方法。这可以通过 token_limits.post_instructions 配置来控制(如果你使用如下所示的 retention_ratio 类型配置截断)。顾名思义,这控制了响应的最大输入 token 数量,指令 token 除外。将 post_instructions 设置为 1,000 意味着超过 1,000 输入 token 限制的项目将不会发送给模型以生成响应。
截断会使对话开头的缓存失效,如果每次轮次都发生截断,缓存命中率将会非常低。为了缓解这个问题,客户端可以将截断配置为丢弃比必要数量更多的消息,这将扩大需要再次截断之前的余量。这可以通过 session.truncation.retention_ratio 设置来控制。服务器默认值为 1.0 ,这意味着截断操作将仅移除必要的项目。值为 0.8 表示截断将保留最大值的 80%,额外丢弃 20%。
如果你试图降低每次会话的 Realtime API 成本(针对特定模型),我们建议减少限制 token 数量,并将 retention_ratio 设置为小于 1,如下例所示。请记住,这可能在降低成本的同时,也会牺牲特定轮次的模型记忆能力。
1
2
3
4
5
6
7
8
9
10
11
12
{
"event": "session.update",
"session": {
"truncation": {
"type": "retention_ratio",
"retention_ratio": 0.8,
"token_limits": {
"post_instructions": 8000
}
}
}
}截断也可以被完全禁用,如下所示。禁用后,如果对话太长而无法创建响应,将返回错误。如果你打算手动管理对话大小,这可能很有用。
1
2
3
4
5
6
{
"event": "session.update",
"session": {
"truncation": "disabled"
}
}其他优化策略
使用 mini 模型
Realtime speech2speech 模型分为“常规”尺寸和 mini 尺寸,后者要便宜得多。这里的权衡通常体现在与指令遵循和函数调用相关的智能水平上,mini 模型在这些方面效果会有所打折。我们建议首先使用较大的模型测试应用程序,完善你的应用程序和提示,然后再尝试使用 mini 模型进行优化。
编辑对话
虽然截断会在服务器上自动发生,但另一种成本管理策略是手动编辑对话。API 的一个原则是允许客户端完全控制服务器端的对话,允许客户端随意添加和删除项目。
1
2
3
4
{
"type": "conversation.item.delete",
"item_id": "item_CCXLecNJVIVR2HUy3ABLj"
}清除旧消息是减少输入 token 大小和成本的好方法。这可能会移除重要内容,但一种常见的策略是用摘要替换这些旧消息。可以使用如上所述的 conversation.item.delete 消息从对话中删除项目,并可以使用 conversation.item.create message.
估算成本
鉴于 Realtime API token 使用情况的复杂性,提前估算成本可能很困难。一个好方法是使用 Realtime Playground 结合你打算使用的提示和函数,测量示例会话的 token 使用量。会话的 token 使用情况可以在 Realtime Playground 中会话 ID 旁边的“日志”选项卡下找到。