
GPT 中的 action 可以执行的最常见任务之一就是数据检索。一个 action 可以:
- 访问 API 以根据关键字搜索检索数据
- 访问关系数据库以根据结构化查询检索记录
- 访问向量数据库以根据语义搜索检索文本块
在本指南中,我们将探讨特定于各种类型检索集成的一些注意事项。
使用 API 进行数据检索
许多组织依赖第三方软件来存储重要数据。例如,用 Salesforce 存储客户数据,用 Zendesk 存储支持数据,用 Confluence 存储内部流程数据,以及用 Google Drive 存储业务文档。这些提供商通常提供 REST API,使外部系统能够搜索和检索信息。
在构建 action 以与提供商的 REST API 集成时,请先查看现有文档。您需要确认以下几点:
- 检索方法
- 搜索 - 每个提供商支持不同的搜索语义,但通常您会想要一个接受关键字或查询字符串并返回匹配文档列表的方法。参见 Google Drive 的
file.list方法 for an example. - 获取 - 一旦找到匹配的文档,您需要一种检索它们的方法。参见 Google Drive 的
file.get方法 for an example.
- 搜索 - 每个提供商支持不同的搜索语义,但通常您会想要一个接受关键字或查询字符串并返回匹配文档列表的方法。参见 Google Drive 的
- 身份验证方案
- For example, Google Drive 使用 OAuth 来对用户进行身份验证,并确保仅检索其可用的文件。
- OpenAPI 规范
- 某些提供商会提供 OpenAPI 规范文档,您可以直接将其导入到您的 action 中。参见 Zendesk,作为一个例子。
- 您可能希望移除对您的 GPT 不会 访问的方法的引用,这会限制您的 GPT 可以执行的 action。
- For providers who 不 提供 OpenAPI 规范文档,您可以使用 ActionsGPT (由 OpenAI 开发的 GPT)创建您自己的文档。
- 某些提供商会提供 OpenAPI 规范文档,您可以直接将其导入到您的 action 中。参见 Zendesk,作为一个例子。
您的目标是让 GPT 使用 action 来搜索和检索包含与用户提示相关的上下文的文档。您的 GPT 会遵循您的指示,使用提供的搜索和获取方法来实现此目标。
使用关系数据库进行数据检索
组织使用关系数据库来存储与其业务相关的各种记录。这些记录可以包含有用的上下文,有助于改进 GPT 的响应。例如,假设您正在构建一个 GPT 来帮助用户了解保险理赔的状态。如果 GPT 可以根据理赔号码在关系数据库中查找理赔,那么它对用户的作用就会大得多。
在构建 action 以与关系数据库集成时,有几点需要注意:
- REST API 的可用性
- 许多关系数据库本身并不公开用于处理查询的 REST API。在这种情况下,您可能需要构建或购买中间件,使其位于您的 GPT 和数据库之间。
- 此中间件应执行以下操作:
- 接受正式的查询字符串
- 将查询字符串传递给数据库
- 将返回的记录回复给请求者
- 从公共互联网的可访问性
- 与设计为可从公共互联网访问的 API 不同,关系数据库传统上设计为在组织的应用程序基础结构内使用。由于 GPT 托管在 OpenAI 的基础结构上,您需要确保公开的任何 API 都可以在防火墙外部访问。
- 复杂的查询字符串
- 关系数据库使用诸如 SQL 之类的正式查询语法来检索相关记录。这意味着您需要向 GPT 提供额外的指示,说明支持哪种查询语法。好消息是,GPT 通常非常擅长根据用户输入生成正式查询。
- 数据库权限
- 尽管数据库支持用户级别的权限,但您的最终用户很可能没有直接访问数据库的权限。如果您选择使用服务账户提供访问权限,请考虑赋予该服务账户只读权限。这可以避免无意中覆盖或删除现有数据。
您的目标是让 GPT 编写与用户提示相关的正式查询,通过 action 提交查询,然后使用返回的记录来增强响应。
使用向量数据库进行数据检索
如果您想为 GPT 配备最相关的搜索结果,您可以考虑将 GPT 与支持如上所述语义搜索的向量数据库集成。市场上有许多托管和自托管的解决方案, 此处提供部分列表.
在构建 action 以与向量数据库集成时,有几点需要注意:
- REST API 的可用性
- 许多关系数据库本身并不公开用于处理查询的 REST API。在这种情况下,您可能需要构建或购买中间件,使其位于您的 GPT 和数据库之间(有关中间件的更多信息请见下文)。
- 从公共互联网的可访问性
- 与设计为可从公共互联网访问的 API 不同,关系数据库传统上设计为在组织的应用程序基础结构内使用。由于 GPT 托管在 OpenAI 的基础结构上,您需要确保公开的任何 API 都可以在防火墙外部访问。
- 查询嵌入
- 如上所述,向量数据库通常接受向量嵌入(而非纯文本)作为查询输入。这意味着您需要使用嵌入 API 将查询输入转换为向量嵌入,然后才能将其提交给向量数据库。这种转换最好在 REST API 网关中处理,以便 GPT 可以提交纯文本查询字符串。
- 数据库权限
- 由于向量数据库存储的是文本块而非完整文档,因此很难维护可能存在于原始源文档中的用户权限。请记住,任何能够访问您的 GPT 的用户都将有权访问数据库中的所有文本块,请据此进行规划。
用于向量数据库的中间件
如上所述,用于向量数据库的中间件通常需要做两件事:
- 通过 REST API 公开对向量数据库的访问
- 将纯文本查询字符串转换为向量嵌入
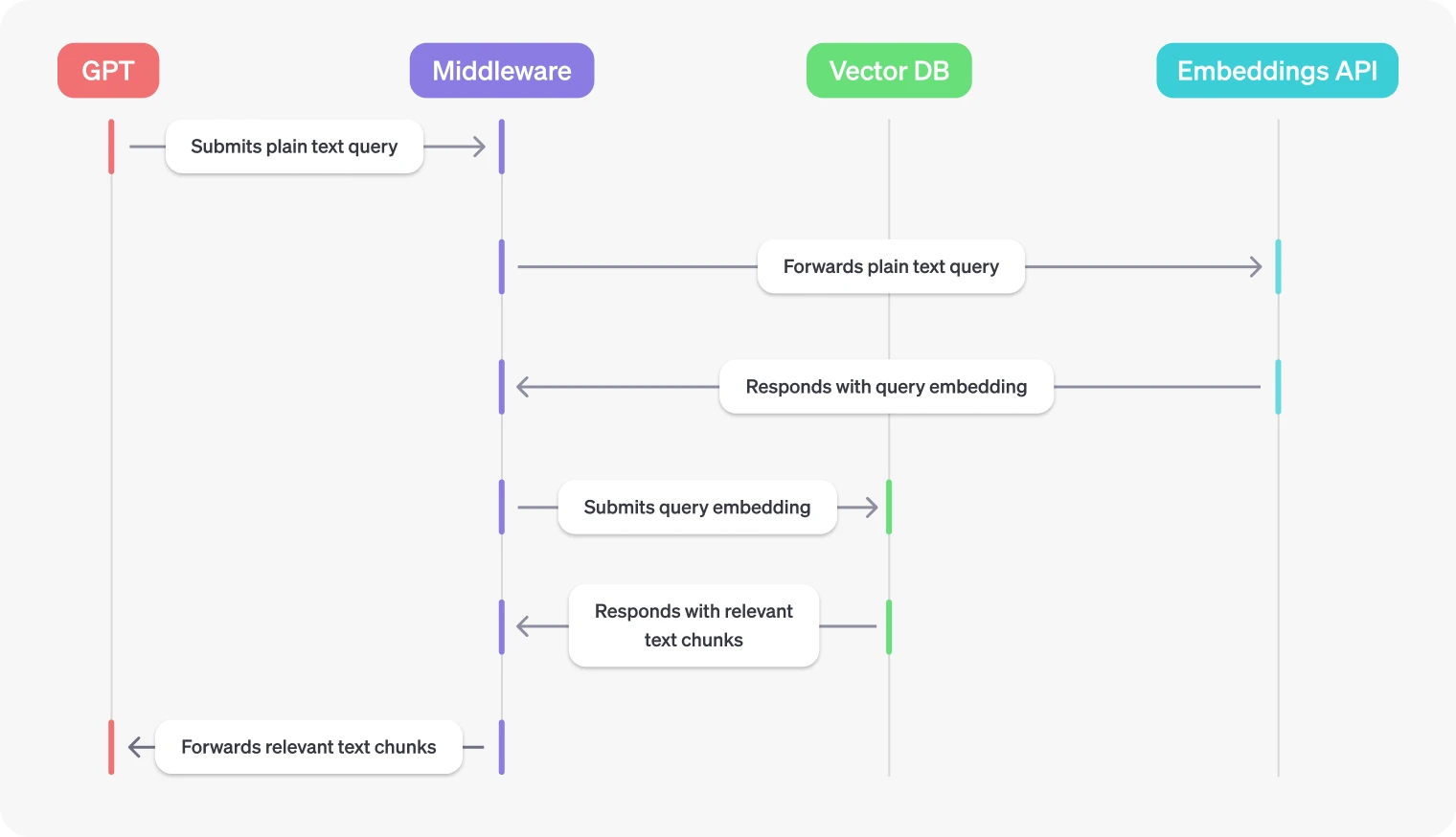
目标是让您的 GPT 向向量数据库提交相关查询以触发语义搜索,然后使用返回的文本块来增强响应。