
如何在使用 LLM 时最大化正确性与行为一致性
优化 LLM 并非易事。
我们曾与众多初创公司和企业的开发人员合作,发现优化之所以困难,往往归结为以下几个原因:
- 知道 如何开始 优化准确性
- 何时使用何种 优化方法
- 准确率达到何种水平才算 足够好 for production
本文提供了一套关于如何优化 LLM 的准确性与行为的心智模型。我们将探讨提示工程、检索增强生成 (RAG) 和微调等方法。我们还将重点介绍如何以及何时使用每种技术,并分享一些常见的陷阱。
在阅读时,请务必在脑海中将这些原则与您特定用例的“准确性”含义联系起来。这似乎是显而易见的事情,但生成一份需要人工修复的低劣文案,与退还客户 1000 美元而非 100 美元,两者的代价截然不同。在讨论 LLM 准确性时,您应该对 LLM 失败的代价以及成功为您节省或带来的收益有一个大致的概念——我们将在结尾探讨生产环境的准确率究竟要达到多少才算“足够好”时再次涉及这一点。
LLM 优化背景
许多关于优化的“操作指南”将其描绘成一个简单的线性流程——从提示工程开始,接着是检索增强生成,然后是微调。然而,实际情况往往并非如此——它们都是解决不同问题的“操纵杆”,为了在正确的方向上进行优化,你需要拉动正确的操纵杆。
将 LLM 优化视作一个矩阵会更有帮助:

典型的 LLM 任务会从左下角的提示工程开始,我们在那里进行测试、学习和评估以建立基线。一旦我们审查了这些基线示例并评估了它们不正确的原因,我们就可以拉动以下其中一个操纵杆:
- 上下文优化: 在以下情况下你需要优化上下文:1) 模型缺乏上下文知识,因为其不在训练数据集中;2) 其知识已过时;3) 它需要专有信息。此轴旨在最大化 响应准确率.
- LLM 优化: 在以下情况下你需要优化 LLM:1) 模型生成的结果不一致或格式错误;2) 语气或说话风格不正确;3) 推理未能保持一致。此轴旨在最大化 行为一致性.
在实际操作中,这会转化为一系列优化步骤:我们进行评估,提出优化假设,应用假设,再次评估,并为下一步重新评估。以下是一个相当典型的优化流程示例:
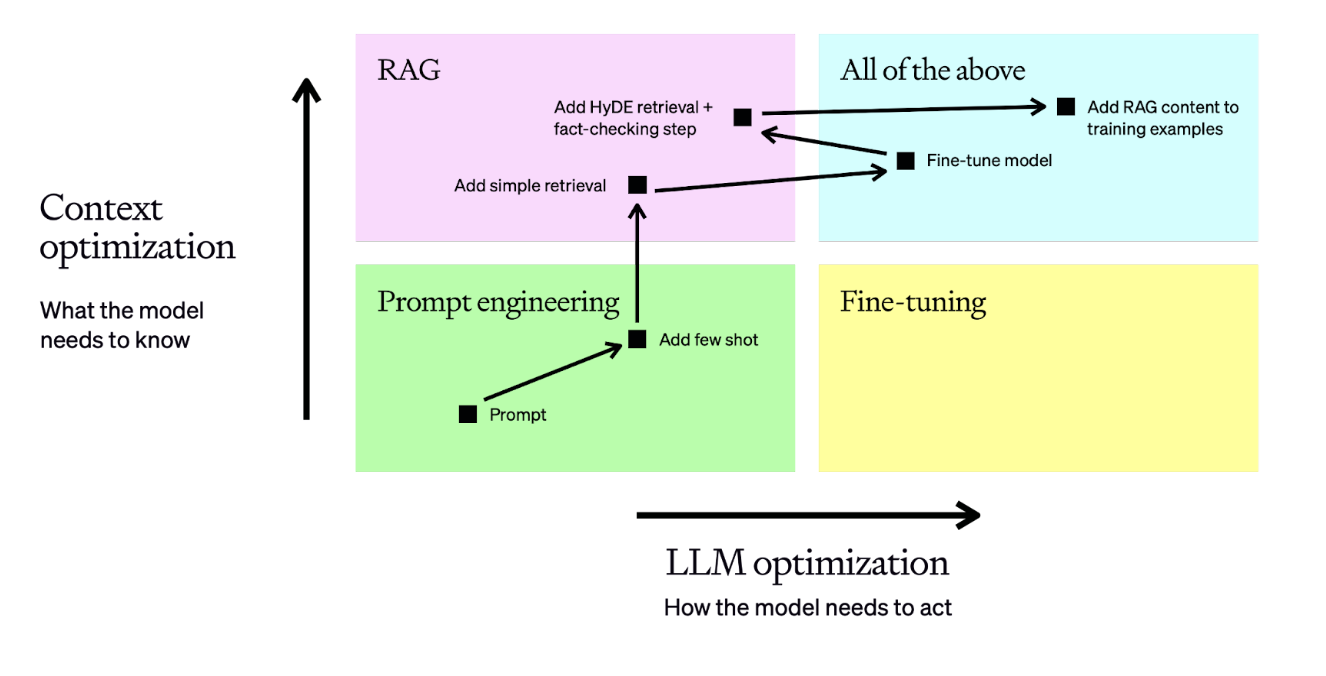
在此示例中,我们执行了以下操作:
- 从一个提示开始,然后评估其表现
- 添加静态少样本示例,这应能提高结果的一致性
- 添加检索步骤,以便根据问题动态引入少样本示例——通过确保每个输入都有相关的上下文,从而提升性能
- 准备一个包含50多个示例的数据集,并对模型进行微调,以提高一致性
- 调整检索过程并添加事实核查步骤以找出幻觉,从而实现更高的准确性
- 使用包含我们增强的 RAG 输入的新训练示例,重新训练微调模型
这是一个针对棘手业务问题相当典型的优化流程——它有助于我们决定是需要更相关的上下文,还是需要模型表现出更一致的行为。一旦做出决定,我们就知道该拨动哪个“控制杆”作为优化的第一步。
现在我们有了一个心智模型,接下来让我们深入了解针对所有这些领域采取行动的方法。我们将从左下角的提示词工程开始。
提示工程
提示词工程通常是最佳的起点**。对于摘要、翻译和代码生成等用例,它往往是唯一需要的方法,因为零样本方法在这些场景下就能达到生产级别的准确率和一致性。
这是因为它会迫使你定义在具体用例中什么是“准确率”——你从最基础的层面提供输入开始,因此你需要能够判断输出是否符合预期。如果结果不符合要求,那么原因 为什么不符合 将指引你进行下一步的优化方向。
为此,你应该始终从一个简单的提示词和预期的输出开始,然后通过添加 上下文, 指令, or 示例 来优化提示词,直到它给出你想要的结果。
优化
为了优化提示词,我将主要借鉴 OpenAI API 文档中 《提示词工程指南》 的策略。每种策略都能帮你调整上下文、LLM,或同时调整两者:
| 策略 | 上下文优化 | LLM 优化 |
|---|---|---|
| 编写清晰的指令 | X | |
| 将复杂任务拆分为更简单的子任务 | X | X |
| 给 GPT 留出“思考”时间 | X | |
| 系统性地测试更改 | X | X |
| 提供参考文本 | X | |
| 使用外部工具 | X |
这些内容可能有点难以想象,因此我们将通过一个实际例子来测试它们。让我们使用 gpt-4-turbo 来纠正冰岛语句子,看看它是如何运作的。
我们已经看到,提示工程是一个很好的起点,并且通过正确的调整方法,我们可以将性能提升到相当高的水平。
然而,提示工程最大的问题在于它通常无法很好地扩展——我们要么需要输入动态上下文,以便模型能够处理比单纯在上下文中添加内容更广泛的问题;要么需要实现比少样本示例更稳定的行为。
Long-context models allow prompt engineering to scale further - however, beware that models can struggle to maintain attention across very large prompts with complex instructions, and so you should always pair long context models with evaluation at different context sizes to ensure you don’t get lost in the middle. “Lost in the middle” is a term that addresses how an LLM can’t pay equal attention to all the tokens given to it at any one time. This can result in it missing information seemingly randomly. This doesn’t mean you shouldn’t use long context, but you need to pair it with thorough evaluation. One open-source contributor, Greg Kamradt, made a useful evaluation called Needle in A Haystack (NITA) which hid a piece of information at varying depths in long-context documents and evaluated the retrieval quality. This illustrates the problem with long-context - it promises a much simpler retrieval process where you can dump everything in context, but at a cost in accuracy.
那么提示工程到底能走多远?答案是视情况而定,而你做出决定的方式就是通过评估。
评估
这就是为什么 一个带有评估问题集和标准答案的优秀提示 是此阶段最佳的产出。如果我们有一组 20 多个问答对,并且深入分析了失败的细节,对其产生的原因提出了假设,那么我们就建立了合适的基线,可以着手采用更高级的优化方法。
在进入更高级的优化方法之前,同样值得考虑的是如何自动化这些评估以加快迭代速度。我们发现以下一些常见做法在这里非常有效:
- 使用诸如 ROUGE or BERTScore 之类的方法来提供一个大致的评估。这与人类评审者的相关性不是特别高,但可以快速有效地衡量每次迭代对模型输出的改变程度。
- 使用 GPT-4 作为评估器,正如 G-Eval 论文中所概述的那样,在其中你为 LLM 提供一个评分标准,以尽可能客观地评估输出。
如果你想深入了解这些内容,请查看 此 cookbook ,它将带你了解所有这些方法的实际应用。
了解相关工具
既然你已经完成了提示工程,拥有了评估集,但模型的表现仍未达到你的要求。此时最重要的下一步是诊断模型在哪里出了问题,以及哪种工具能最好地改进它。
以下是一个用于诊断的基本框架:
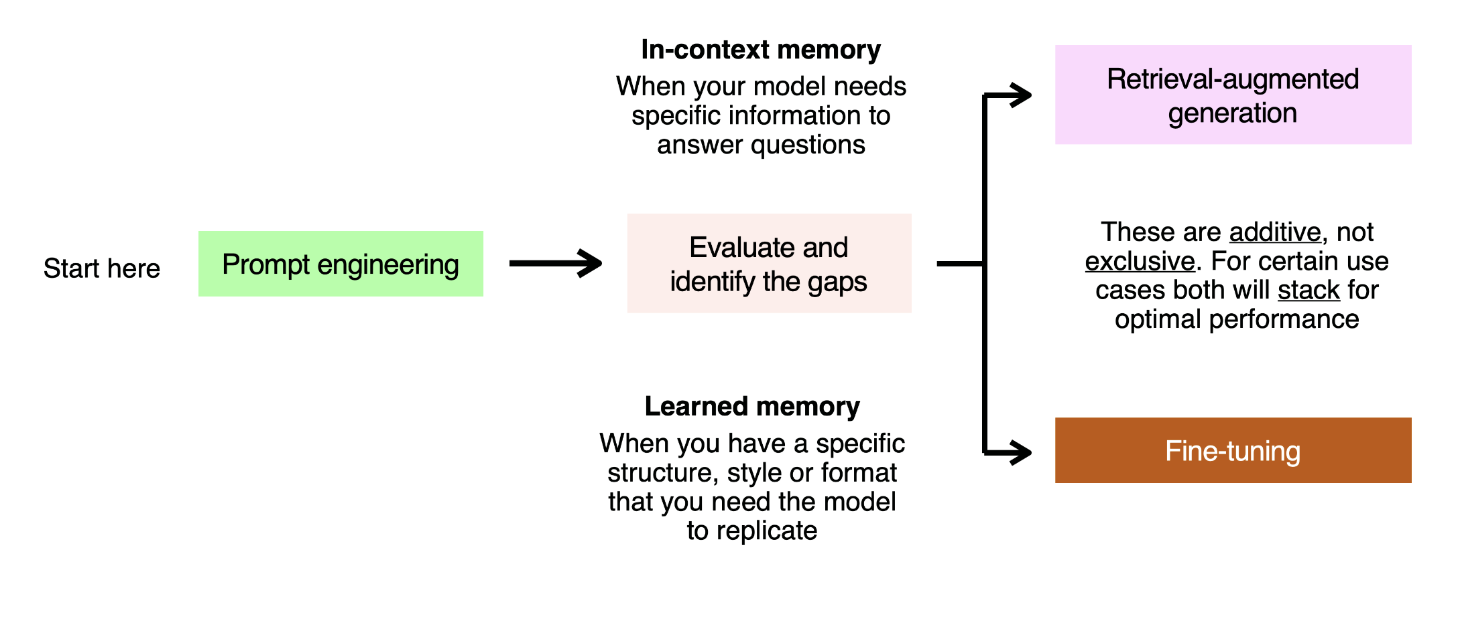
你可以将每个未通过评估的问题看作是一个 in-context or 习得的 记忆问题。打个比方,假设你在参加一场考试。有两种方法可以确保你得出正确答案:
- 在过去 6 个月里你一直上课,看到了大量关于某个特定概念如何运作的重复示例。这就是 习得的 记忆——在 LLM 中,我们通过展示提示词和期望响应的示例,让模型从中学习来解决这个问题。
- 你手头有课本,并且可以查找正确的信息来回答问题。这就是 in-context 记忆——在 LLM 中,我们通过将相关信息填充到上下文窗口中来解决这个问题,既可以使用提示工程以静态方式实现,也可以使用 RAG 以工业化方式实现。
这两种优化方法是 累加的,而非互斥的 ——它们可以叠加使用,某些用例需要将它们结合使用才能实现最佳性能。
假设我们面临的是短期记忆问题——为此我们将使用 RAG 来解决它。
检索增强生成 (RAG)
RAG 是在 R检索内容以 A增强 LLM 提示,然后再 G生成答案的过程。它用于为模型提供 特定领域的上下文访问权限 to solve a task.
RAG 是提高 LLM 准确性和一致性的极其有价值的工具——我们在 OpenAI 实施的许多最大规模的客户部署,仅使用了提示工程和 RAG。
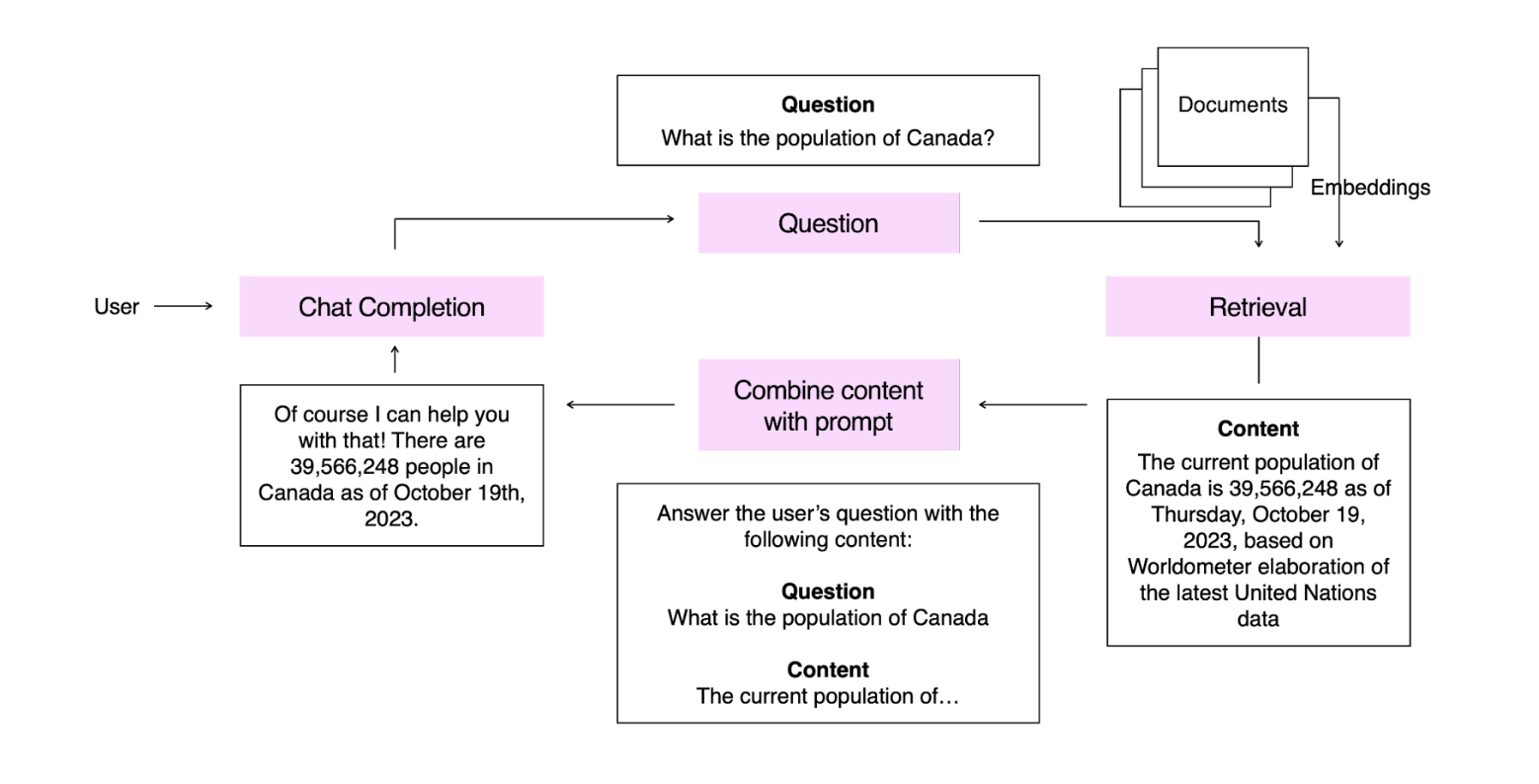
在这个例子中,我们嵌入了一个统计学知识库。当用户提出问题时,我们将该问题进行嵌入,并从知识库中检索最相关的内容。然后将这些内容提供给模型,由模型来回答问题。
RAG 应用引入了一个我们需要优化的新维度,即检索。为了让 RAG 正常工作,我们需要向模型提供正确的上下文,然后评估模型是否做出了正确的回答。我将在这里用一个矩阵来展示一种简单的、用于评估 RAG 的思考方式:
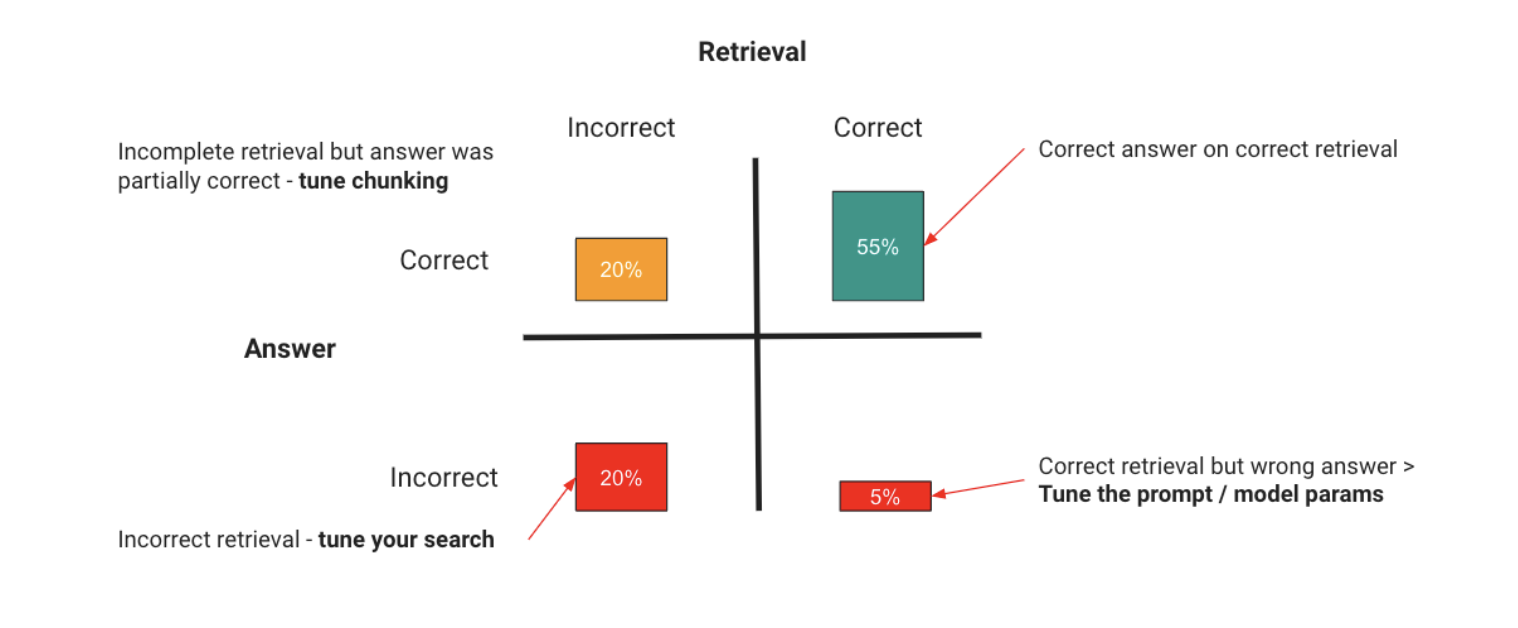
你的 RAG 应用可能在两个方面出现问题:
| 方面 | 问题 | 解决方案 |
|---|---|---|
| 检索 | 你可能提供了错误的上下文,导致模型根本无法回答;或者提供了过多无关的上下文,淹没了真实信息并导致幻觉产生。 | 优化你的检索,具体可以包括: - 调整搜索以返回正确的结果。 - 调整搜索以减少噪音。 - 在每个检索结果中提供更多信息 这些只是示例,因为调优 RAG 性能本身就是一门独立的学问,像 LlamaIndex 和 LangChain 等库提供了许多调优方法。 |
| LLM | 模型也可能获取到了正确的上下文,却对其做出了错误的处理。 | 通过改进模型使用的指令和方法来进行提示工程,并且如果展示示例能提高准确性,则加入微调 |
这里需要掌握的关键点是,其原则与我们最初的心智模型保持一致——你通过评估来找出问题所在,并采取优化步骤来解决它。RAG 唯一的不同在于,你现在多了一个检索维度需要考虑。
虽然 RAG 很有用,但它只解决了我们的上下文学习问题——对于许多用例来说,核心问题在于如何确保 LLM 能够学习某项任务,从而稳定可靠地执行它。针对这个问题,我们求助于微调。
微调
为了解决习得记忆的问题,许多开发者会在较小的、特定领域的数据集上继续 LLM 的训练过程,以针对特定任务对其进行优化。这个过程被称为 微调.
进行微调通常出于以下两个原因之一:
- 提高模型在特定任务上的准确性: 在特定任务的数据上训练模型,通过向其展示大量正确执行该任务的示例,来解决习得记忆问题。
- To improve model efficiency: 以更少的 token 或使用更小的模型来实现相同的准确性。
微调过程首先需要准备一个包含训练示例的数据集——这是最关键的一步,因为你的微调示例必须完全代表模型在真实场景中将会看到的内容。
许多客户使用一种被称为 提示烘烤 (prompt baking),在试点期间,你需要在此过程中详细记录提示的输入与输出。这些日志可以被筛选成包含真实示例的有效训练集。
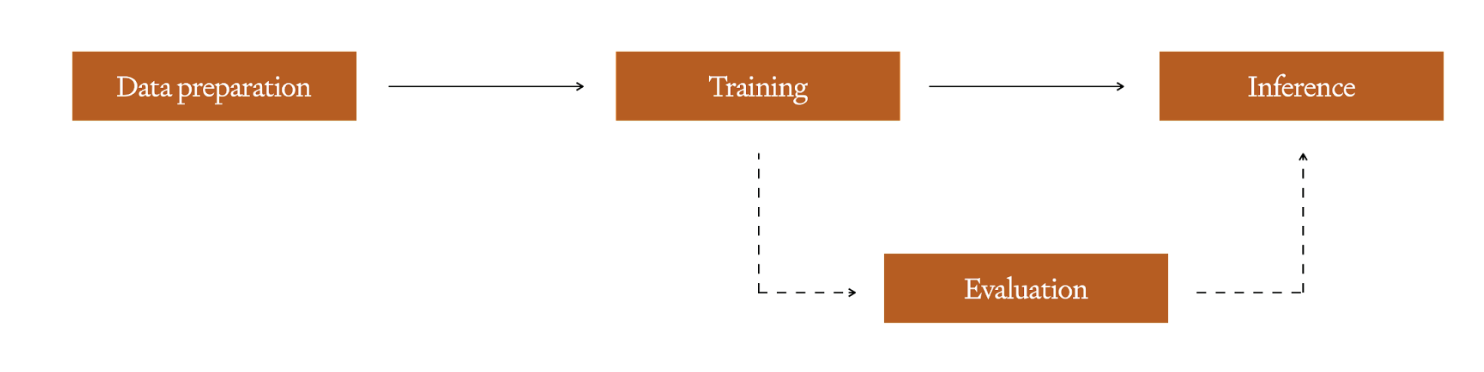
有了这组干净的示例集后,你可以通过执行一次 训练 运行来训练一个微调模型——取决于你用于训练的平台或框架,你可能会有一些可以调整的超参数,这与其他任何机器学习模型类似。我们始终建议保留一个维持集,用于在 评估 训练完成之后检测过拟合。有关如何构建优秀训练集的技巧,你可以查看这份 指南 ,请参阅我们的微调文档。训练完成后,即可使用经过微调的新模型进行推理。
为了优化微调效果,我们将重点关注在 OpenAI 模型定制服务中总结出的最佳实践,但这些原则同样适用于其他提供商和开源 (OSS) 服务。需要注意的关键实践如下:
- 从提示词工程开始: 通过提示词工程建立一套可靠的评估集,作为基线使用。这种低成本投入的方式,能让你在确认基础提示词符合预期之前,避免不必要的资源消耗。
- 从小规模开始,注重质量: 在基础模型上进行微调时,训练数据的质量比数量更重要。建议从 50 个以上的样本开始,并进行评估;如果尚未达到准确率目标,且导致回答错误的原因是缺乏一致性或行为问题而非上下文不足,再逐步增加训练集的规模。
- 确保样本具有代表性: 我们发现最常见的陷阱之一是训练数据缺乏代表性,即用于微调的样本在格式或形式上,与大语言模型 (LLM) 在实际生产环境中遇到的数据存在细微差异。例如,如果你开发的是一个 RAG 应用,请务必在微调时包含 RAG 样本,这样模型就无需再以零样本的方式从头学习如何使用上下文。
综合运用以上方法
这些技术是可以叠加使用的——如果在早期评估中发现上下文和行为同时存在问题,那么最终的落地方案很可能是微调与 RAG 的结合。这完全没有问题——叠加使用可以平衡这两种方法各自的短板。主要的一些优势包括:
- 利用微调来 最小化 Token 消耗 即在提示词工程中减少指令和少样本示例的 Token 使用,转而通过大量训练样本将一致的行为内化到模型中。
- 通过广泛的微调来 教授复杂行为
- 使用 RAG 来 注入上下文、更新的内容或您的用例所需的任何其他专业上下文
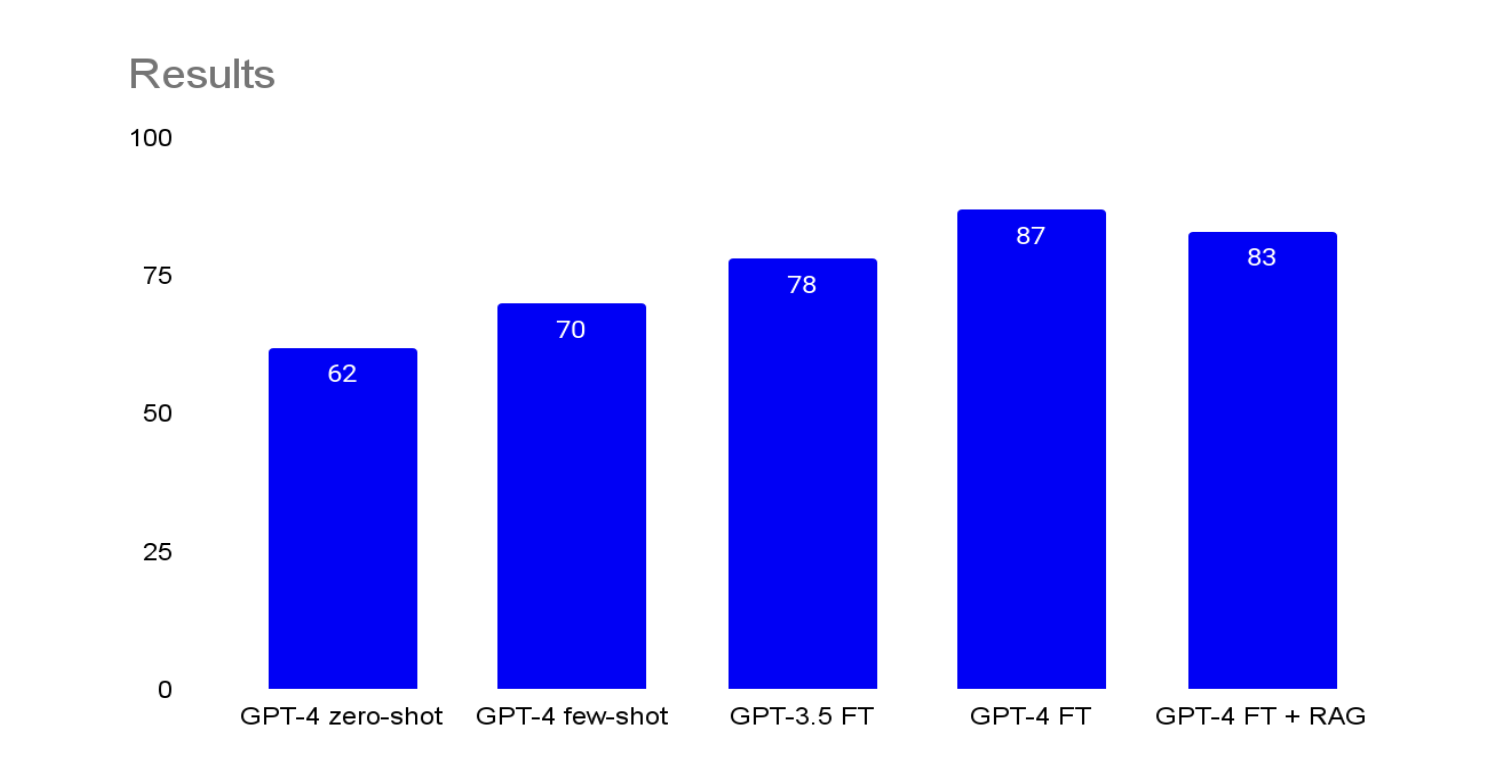 不同微调方法的 Bleu 得分(满分 100)
不同微调方法的 Bleu 得分(满分 100)现在你应该对 RAG 和微调,以及它们各自的适用场景有了深入的了解。关于这些工具,你需要了解的最后一点是,一旦引入它们,我们的迭代速度就会面临一种权衡:
- 对于 RAG,你需要调整检索过程以及 LLM 的行为
- 对于微调,在进行额外调整时,你需要重新运行微调过程,并管理你的训练集和验证集。
这两个过程都可能既耗时又复杂,并且随着 LLM 应用变得越来越复杂,可能会引入回归问题。如果你要从本文中记住一件事,那就是:在转向更复杂的 RAG 或微调之前,尽可能利用基础方法来提升准确率——让你的准确率目标成为目的,不要仅仅因为觉得 RAG + 微调听起来最尖端就盲目追求它们。
对于生产环境来说,多高的准确率才算“足够好”
为 LLM 调优准确率可能是一场永无止境的战斗——使用现成的方法,它们不太可能达到 99.999% 的准确率。本节的核心在于决定何时准确率才算足够——如何放心地将 LLM 投入生产,以及如何管理你所部署解决方案的风险。
我发现从 业务 and 技术 上下文。我将介绍管理两者的高层方法,并使用客服服务台的用例来说明我们在这两种情况下如何管理风险。
业务
对于企业而言,在体验过基于规则的系统、传统机器学习系统甚至人类带来的相对确定性后,很难再轻易信任 LLM。一个失败情况开放且不可预测的系统,是一个难以调和的矛盾。
我曾在一个客服用例中见证过一种成功的应对方法——为此,我们采取了以下措施:
首先,我们确定主要的成功和失败情况,并为其分配预估成本。这让我们能够清晰地说明,基于试点表现,该解决方案可能会节省或耗费的成本。
- 例如,一个原本由人工解决的案例现在由 AI 解决,这可能会节省 $20.
- 有人在不该被升级处理时被升级给了人工,这可能会耗费 $40
- 在最坏的情况下,客户对 AI 感到非常沮丧并流失,导致我们损失 $1000。我们假设这种情况在 5% 的情况下发生。
| 事件 | 值 | 案例数量 | 总价值 |
|---|---|---|---|
| AI 成功 | +20 | 815 | $16,300 |
| AI 失败(升级处理) | -40 | 175.75 | $7,030 |
| AI 失败(客户流失) | -1000 | 9.25 | $9,250 |
| 结果 | +20 | ||
| 盈亏平衡准确率 | 81.5% |
我们做的另一件事是衡量流程的经验统计数据,这将帮助我们衡量解决方案的宏观影响。再次以客服为例,这些数据可能是:
- 纯人工交互与 AI 交互的客户满意度 (CSAT) 评分
- 人工与 AI 的历史回顾案例决策准确率
- 人工与 AI 的解决时间
在客服示例中,这帮助我们在进行几次试点获得明确数据后,做出了两个关键决策:
- 即使我们的 LLM 解决方案升级至人工的频率超出预期,它仍然比现有解决方案节省了巨大的运营成本。这意味着,即使准确率只有 85% 也是可以接受的,前提是那 15% 的失误主要是早期的升级处理。
- 在失败成本非常高的情况下,例如欺诈案件被错误处理,我们决定由人工主导,而 AI 作为辅助。在这种情况下,决策准确率数据帮助我们做出判断:我们无法接受完全的自主运行。
技术
在技术方面则更为清晰——既然业务部门已经明确了他们期望的价值以及出错可能带来的成本,你的职责就是构建一个能够优雅处理失败的解决方案,且不破坏用户体验。
让我们再次使用客服示例来说明这一点,并假设我们有一个在判断意图方面准确率为 85% 的模型。作为技术团队,我们可以通过以下几种方式将这错误率 15% 的影响降至最低:
- 我们可以通过提示工程,让模型在不自信时提示客户提供更多信息。因此,我们的首次准确率可能会下降,但在给定两次机会判断意图的情况下,整体准确率可能会更高。
- 我们可以赋予二线助理回退至意图判断阶段的选项,这再次为用户体验提供了一种自我修复的途径,代价是增加一些用户延迟。
- 我们可以通过提示工程,让模型在意图不明确时移交给人工。这会在短期内消耗掉部分运营成本节省,但在长期内可能会抵消客户流失的风险。
这些决策随后会融入我们的用户体验设计中,虽然以牺牲速度换取了更高的准确率,或者导致了更多的人工介入,但这都会计入上文业务部分所涵盖的成本模型中。
现在,你拥有了一套方法,能够拆解设定准确率目标时涉及的业务与技术决策,并且该目标是立足于业务实际情况的。
后续步骤
这是一个高层级的思维模型,用于思考如何最大化 LLM 的准确率、可用于实现这一目标的工具,以及如何决定达到何种标准即可投入生产。你已经掌握了持续交付至生产环境所需的框架和工具,如果你想从其他人使用这些方法取得的成果中获取灵感,请查看我们的客户案例,诸如 Morgan Stanley and Klanna 展示了通过利用这些技术所能取得的成就。
祝你顺利,我们非常期待看到你以此构建出精彩的产品!